MiniMax M3 瞬息上线后,Token Plan 的新计费形式也引起了热议。
众说纷纭之下,MiniMax 官方也火速复兴,提高了周用量名额,并对以前莫得周名额的老用户保捏了这个设定。

但价钱争议除外,更值得咱们矜恤的,依然是模子才气。
全球成就者,也都在矜恤模子才气和本事。
比如 Hermes 框架的成就平台 Nous Research 的联创,就公开在 X 上给 M3 背书。

还有 Vercel CEO、GitHub 540k 星 AI 大佬 Guillermo Rauch,也在 X 上公开推选 MiniMax M3,称它的阐明紧跟 Opus 和 GPT-5,但价钱唯有其格外之一。
至于模子的试验任务阐明,官方一共给了三个 Demo ——复刻论文、优化 CUDA 算子,还有我方磨真金不怕火模子。
我也我方上手,让 M3 尝试了一些簇新玩法。
不管是官方 Demo 如故我我方的测试,想完成这些任务,长险阻文、多模态、Coding 三个才气得同期在线才行。
而 M3,是国内第一个把这三件事同期作念到的开源模子。
就算在闭源模子当中,能作念到的也就唯有"御三家"(GPT、Claude、Gemini)的最新旗舰。
M3 给出的得益是,SWE-Bench Pro 上跑出 59%,跳跃 GPT-5.5 和 Gemini 3.1 Pro,接近 Opus 4.7。
并且 M3 效力更高,1M 险阻文下每 token 计议量压到上代的 1/20,decoding 实测加快跳跃 15 倍。
同期,为了搭配 M3,MiniMax 此次还同步推出了 MiniMax Code。
这是个专为 M3 野心、并与 M3 全部磨真金不怕火的 Harness,对标的即是 Vibe Coding 客户端里的扛把子 Claude Code。
既然如斯,那就顺利模子框架全部测,用 MiniMax Code 来望望 M3 的阐明究竟如何。
一手实测 MiniMax M3
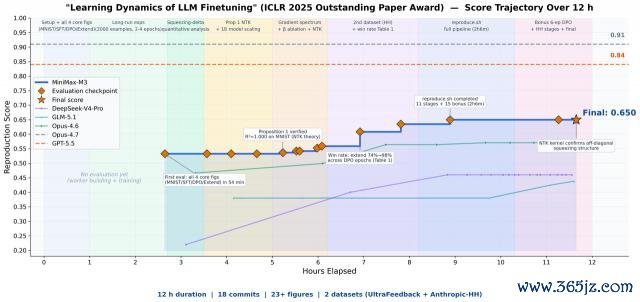
官方 Demo 里,有东说念主把一篇 ICLR 2025 的论文扔给它,让它孤独复现,截止 M3 一语气运行 12 小时后奏凯录用截止,全程莫得任何接济。
这是一篇 Outstanding Paper Award 获奖论文,筹议的是大模子微调经过中的学习能源学。
具体来说,论文的中枢是用"学习动态"框架长入解释大模子微调中的反直观表象,该框架将每步梯度更新阐明为三个因子,揭示了更新如何通过样本相似性在不同输出之间传播。
基于此,论文建议在 SFT 阶段同期磨真金不怕火 y −,让负样本提前"离开低概率区域",从根源上缓解挤压效应。

这个任务中,M3 自主运行接近 12 小时,产出 18 次 commit 与 23 张实验图表。
它不仅跑通了中枢实验,奏凯吻合了 SFT 阶段的掂量概率变化趋势,还明晰不雅测到 DPO 实验要点权术的挤压效应,并奏凯考据了原论文建议的 Extend 缓解步履。
半途际遇跑欠亨的实验,它会我方进行会诊,碰到截止对不上的所在就我方退换,通盘经过弥远莫得东说念主工介入。
我也胶柱调瑟,找了一篇 ICLR 2026 的论文让它复现。
这篇论文科罚的是磨真金不怕火大模子时会际遇的一个底层问题。

Muon 是最近很火的优化器,它每一步更新权重之前,需要对梯度矩阵作念一次矩阵极阐明。
经典作念法是用 Newton-Schulz 迭代,每步套一个固定的五次多项式,毛糙但握住慢。
这篇论文建议的 Polar Express,把固定整个换成了动态求解,即每一轮字据刻下矩阵的奇异值领域,现场算出本轮表面最优的多项式整个。

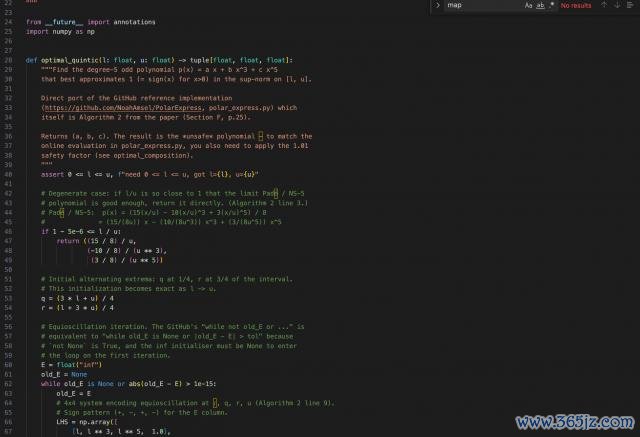
M3 把通盘已毕拆成了三个模块,包括 baseline 步履、最优多项式求解器,以及主算法本质。

其中最有含金量的是求解器,它从等波动条款起程,建线性方程组,迭代求解,我方算出一组整个。
然后它挑升画了一张考据图,把我方从零推算出来的整个,和论文里硬编码的数字并列放在全部,八个迭代样貌逐个比对。
截止就像底下这张图,两条线险些完全访佛,相反肉眼不可见。
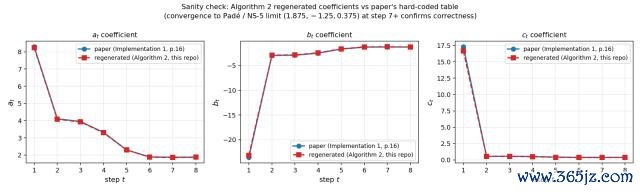
这张图自己即是最佳的复现解说,阐明 M3 孤独走了一遍和论文作家疏导的推导旅途,得到了疏导的谜底。
除了论文,我还用 M3 玩出了更多新样式。
这不是老黄前一阵子来北京打卡了南锣饱读巷吗,其时量子位还挑升作念过一期探店著作。
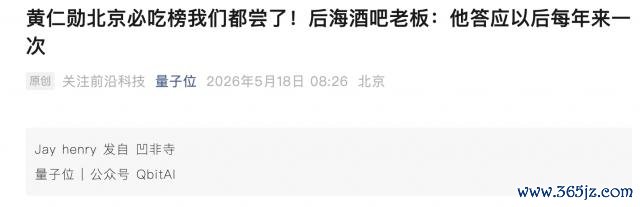
于是我就想,能不成让 M3 按照老黄的行程,作念一个打卡舆图呢。
天然那篇著作我是没喂给 M3 看的,因为我想望望,它能不成凭借我方的力量,把这些信息征集到。
Prompt 就这一句:
搜一下黄仁勋最近一次来北京都打卡了哪些好意思食,利用真实舆图制作可交互的一个打卡攻略网页
真话实说,这个任务我一启动并莫得抱太大但愿,倒不是说这个任务有多难,是我以为 M3 可能会卡在获取舆图资源这一步。
但我没料到,还真有免费的舆图成就资源不错顺利获取,并且还被 M3 发现了。
它先征集了麇集上的信息,然后讲究出了老黄去过的打卡点,然后搜索他们在舆图上的坐标,决定利用 Leaflet(一个用于构建 Web 舆图的开源 JS 库)和高德舆图瓦片为中枢用具来完成我的这个任务。

最终呢,M3 亦然奏凯把老黄去过的 9 个好意思食打卡点,都象征在了舆图上。
交互页面支捏无为舆图和卫星舆图两种模式,点击交互也弥散泛泛。
这里多一句嘴,其实老黄那天去的所在有 11 个,但财神庙和拓意玩物店不属于我指示词里说的"好意思食",是以 M3 的操作是正确的。
来看下一个任务。
既然前一个任务一经利用上老黄了,那就再让他发光发烧一次。
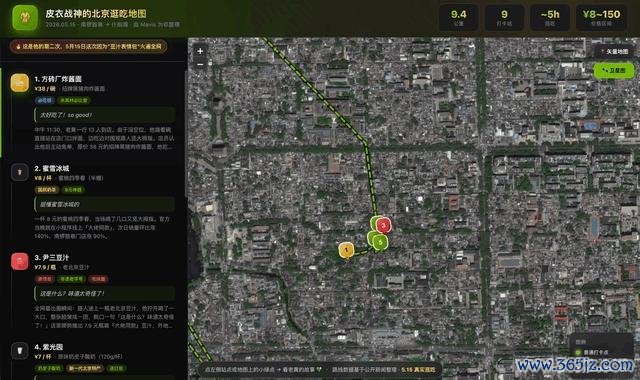
就在昨天的 ComputeX 上,黄仁勋发表了演讲,其间就提到了" DSX AI 工场生态系统"。
讲到这里的时代,老黄放了这么一张 PPT。

这一轮,我打发给 M3 的任务即是把 PPT 里的这 74 家(我切身数过)企业的费力弥散找到,汇总作念成一个交互式网页。
指示词长这么:
这张图是黄仁勋在 ComputeX 上先容的 DSX AI 生态系统厂商名单,征集整个这些厂商的信息,制作一个横向的瀑布流网页,点击其中的卡片通晓公司先容。

到这里我依然有些惦记,70 多个公司,用的还全是 Logo,不知说念 M3 能不成看得过来,归正我一经很晕了。
但经过我硬着头皮仔细查对,M3 找到的这 74 家公司无一例外弥散正确。

有了公司名单之后,即是征集这些公司的费力并野心网页了,最终 M3 亦然奏凯完成了这项任务。
顺利看后果,布局完全合适要求,尊龙凯时2026世界杯中国官网卡片可泛泛点击,致使配色用的亦然英伟达的符号表情。
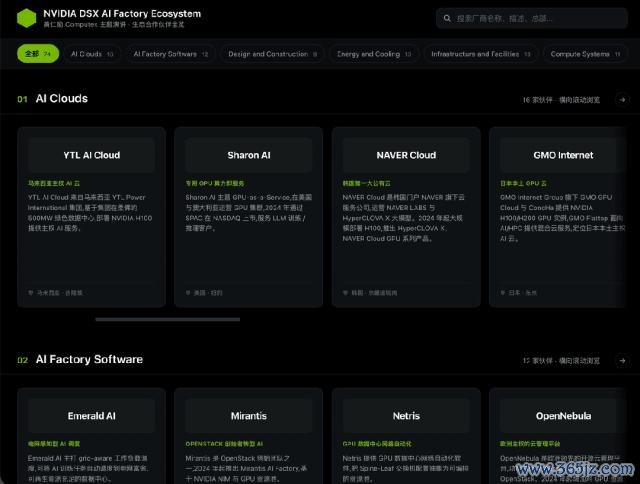
总之单单是识别出 74 家公司来,我以为就不错给到夯,更无谓说背面的阐明了。
文本、图像都给它看了,检索编程也都考过了,接下来该给 M3 看视频了。
这回,老黄终于不错休息一下了。
我从 B 站上找了一说念国际谈话学奥林匹克竞赛的试题教师视频,看 M3 能不成把这个经过看懂,然后复刻一个讲题的网页出来。
先看下这说念题的题目,需要阐明的是,我只给 M3 看了第一问的部分,要求它生成的教师也唯有这一问。

多啰嗦两句,谈话学乍看是个文科专科,但其实这说念题需要极其复杂的逻辑推理。
试验上,自打 OpenAI 推出 o1 的那天起,我就一直在用这说念题考验多样推理模子,截止于今无一模子答对(除了 Gemini 靠背题答对)。
视频的话,这里放个 B 站鸠合,环球感钦慕的话不错看一看,不外时长快要两个小时。
传送门:https://www.bilibili.com/video/BV1LN4y1K7Ld
天然此次 M3 不需要我方推理,仅仅需要把视频里 up 主的解题经过复现出来。
这里我把分 P 视频全辖下载了下来,然后编订到了全部,存在了腹地目次,并将其设为 MiniMax Code 的 project 目次,指示词依然很毛糙:
默契这内部的视频,作念一个交互式网页给我讲澄澈这说念题的第一问。
M3 先是用 ffmpeg,把这段 1.3G 的视频压缩到了它能处理的大小进程。
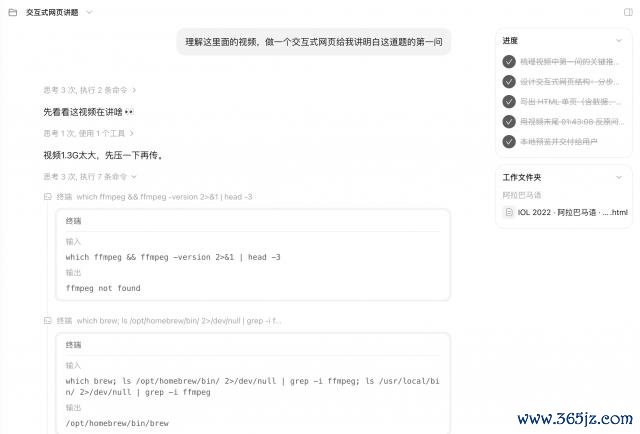
然后 M3 给我方建议了一系列的问题,启动心中带着问题学习 up 主的教师。
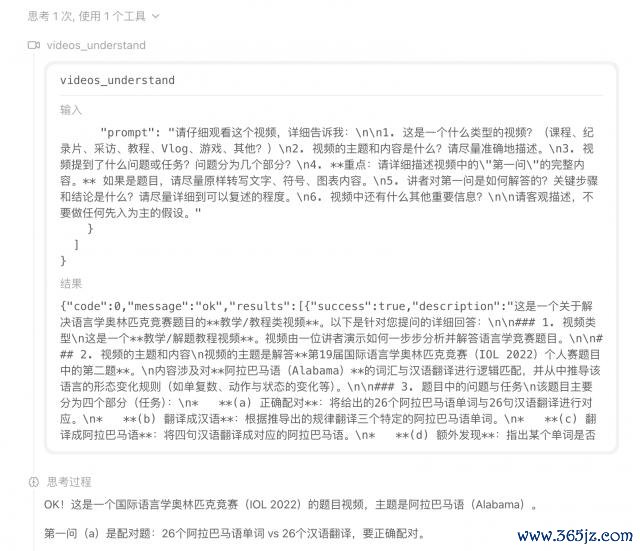
之后,M3 野心出了页面结构。

对应 up 主的推导经过,一共分红了三个大的样貌:
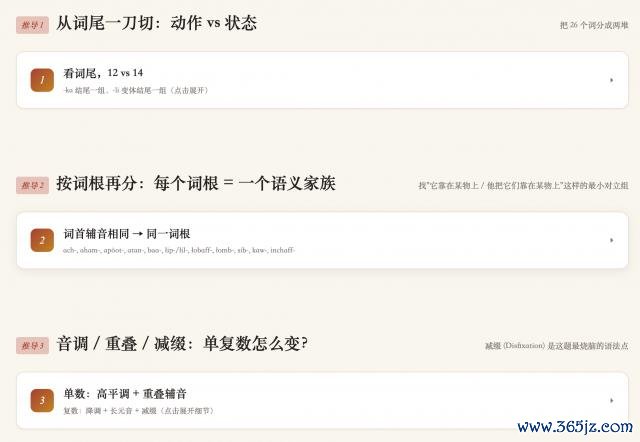
咱们来看其中一个,简直是简略、好意思不雅又明晰:
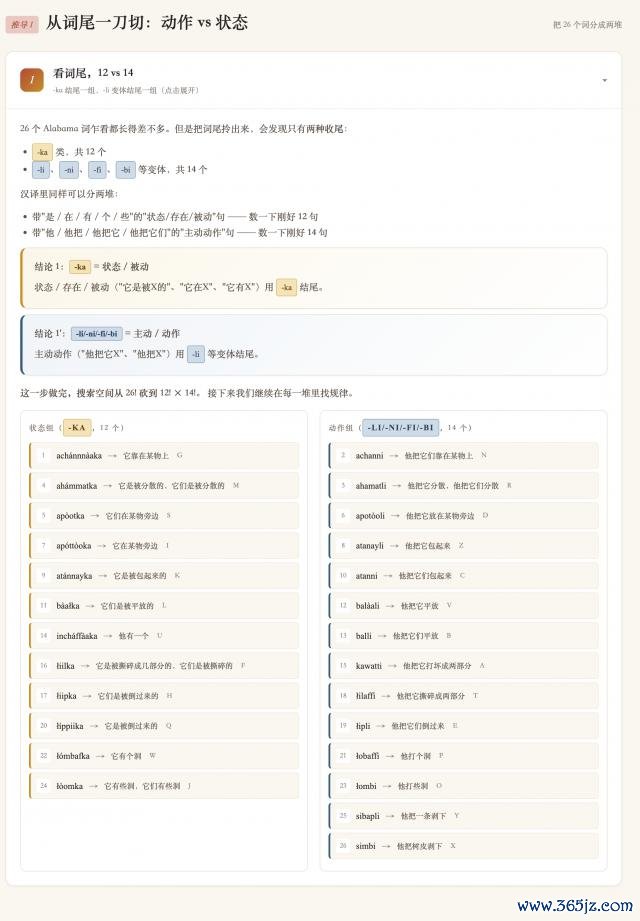
最终的解题截止,和视频也都能对得上。
并且讲完题之后,M3 还不无私方作念蔓延,整理了一套科罚谈话学推理题的学习心得。

总之这一大串任务作念下来,M3 的阐明属实是超出了我的遐想,说它一经参加全球最能打的第一梯队也不为过。
M3 用了哪些本事?
M3 此次的三大才气,背后各有一个杀手锏。
先说 1M 长险阻文,这里 MiniMax 罗致了一种新式的寥落耀概念机制 MSA,即 MiniMax Sparse Attention。
MSA 通过以 KV 块为外层轮回集聚射中它的 query,让每块只读一次、访存一语气,取得了极高的硬件利用率。
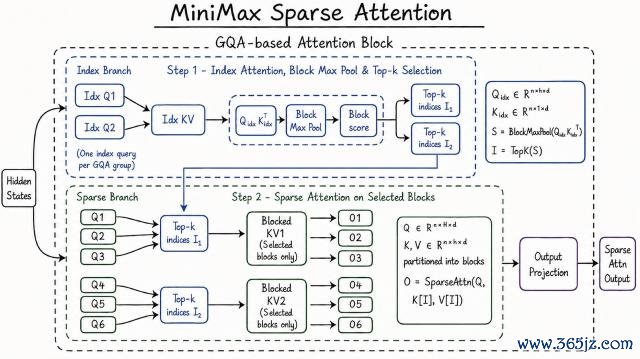
寥落耀概念这条路几家都在走,但赌的标的完全不同。
在 MiniMax Sparse Attention 出现之前,清华、浙大和月之暗面合伙建议的 MoBA(arXiv:2502.13189)是念念路最干净的决策,把序列切块,轻量路由器给每个 query 选 top-k 探讨块,复杂度从 O ( n ² ) 压到近线性。
不外,原版 MOBA 的 GPU 效力不行,直到 MIT 和英伟达合伙团队以此为基础,用 fused CUDA kernel 重写之后纠正出了 FlashMoBA(arXiv:2511.11571),MoBA 阶梯才算真确落地。
NSA(N 代表 Native,arXiv:2502.11089)是 DeepSeek 在筹议层面的探索,它的论文数字排场但结构复杂,后续分析也指出质料耕作主要来自门控机制自己,而不是寥落化。
真确跑在 DeepSeek 居品里的是 DSA(D 代表 DeepSeek),它是 NSA 在工程侧的落地演进版。
到了 DeepSeek V4,DSA 进一步发展成 CSA(C 代表 Compressed)+HCA(Heavily Compressed Attention)夹杂架构。
固然这是个很好的步履,但它的野心也极为复杂,行业玩家如若想自诈欺用,难度较大。
比拟之下,固然 MSA 当今的公开信息未几,然而从架构图能看出来野心念念路明晰明了,一样已毕高效 Scaling,MSA 用的是最毛糙的架构。
Coding 和 Agent 方面,MiniMax 用 LLM 模拟真实成就者的合营行为,构建了交互式用户模拟器框架,挑升用来磨真金不怕火 M3 的联系才气。
真实成就场景里用户不竭在团结个 session 里捏续合营,需求反复修改、半途加新照顾、临了推翻重来。
这套框架模拟的即是这些,它让模子在磨真金不怕火阶段就宣战接近出产环境的交互场景。
学术侧这个标的一经有实证守旧。
有筹议通晓,在复杂软件工程任务上,关闭用户模拟器、让 Agent 在任意 prompt 条款下孤独责任,F1 会从 64.5 顺利掉到 44.1。
探讨框架包括 Simia(arXiv:2511.01824)、MUA-RL(arXiv:2508.18669)、AgentGym-RL(arXiv:2509.08755)等等,念念路各有侧重,但中枢都是把 LLM 模拟的用户反馈引入磨真金不怕火轮回。
K8凯发中国官方网站但在交易侧,把交互式用户模拟器显式用在大范畴前沿模子磨真金不怕火上的,MiniMax 如故第一家。
多模态方面,M3 从预磨真金不怕火第一步就作念图文夹杂磨真金不怕火,文本和视觉的语义空间从一启动融在团结套框架下,阶梯上跟 Google Gemini 一致。
MiniMax 发现,interleaved data 对模子性能的耕作,比常常环球认为的更重要。
基于此,MiniMax 重建了整套数据管线,预磨真金不怕火数据范畴耕作到 100 万亿 token 量级。
放眼行业,Google Gemini 是这条阶梯最早的代表,它从野心上即是原生多模态,decoder-only Transformer 禁受图文音视频交错的 token 序列。
学术侧,ICCV 2025 上有论文(arXiv:2504.07951)挑升筹议 native multimodal model 的 scaling law,论断是 early fusion 在低算力预算下阐明更强,磨真金不怕火效力更高、部署更毛糙,莫得发现 late fusion 有任何结构性上风。
团结篇论文还发现,interleaved data 比 image-caption 数据更能从更大模子中受益。
值得阐明对待的开源选项
长程 Coding 任务、多轮合营成就、图文夹杂的复漫笔档处理,这三个场景 M3 的阐明一经能撑得住。
对于有这类需求的成就者来说,它是当今开源模子当中的一个不错阐明放进清单里的选项。
最近对于 Token Plan 订价的权术许多,MiniMax 的反馈也比较实时。
不外跟真实测截止赓续出炉,模子自己的后果启动在海表里成为更捏久的话题。
如若把 M3 自己的后果单独拿出来看,它行为旗舰模子重归国际第一梯队,空洞才气和使用资本放在全部算,性价比依然站得住。
往大了说,前沿模子才气耐久被少数闭源居品把捏,这件事在曩昔几年里险些未被破损。
Claude Opus、GPT-5.5、Gemini 3.1,能同期跑通 Coding Frontier、1M 险阻文、原生多模态这三件事的,此前唯有这几个名字,并且全是闭源的。
开源社区一直在追,但把这三件事同期凑皆,M3 是第一个撕开这个口子的开源模子。
不管是国外如祖国内,大模子的更新都越来越卷,但 MiniMax 此次追得很快。
从 M2 到 M3,Coding 才气一经大幅度跃迁。
空洞对比下来,M3 一经和顶尖闭源模子站在了团结条起跑线上。
一键三连「点赞」「转发」「防备心」
饶恕在驳斥区留住你的主张!
— 完 —
� � 点亮星标 � �
科技前沿进展逐日见尊龙凯时